
摘要:本篇文章将详细解析如何编写禁止百度收录的robots.txt代码,并提供使用技巧及注意事项。禁止百度收录的注意事项txt文档的基础知识及其与百度收录之间的关联,同时强调了配置文件的技术要点及注意事项。
在数字化时代背景下,互联网搜索引擎对于人们生活至关重要,百度作为国内最大搜索引擎之一,对站长运营具有举足轻重的影响。然有时对于某些网页,站长不希望其被百度收录,此时便需借助robots.txt文件进行设定。本篇文章将详细解析如何编写禁止百度收录的robots.txt代码,并提供使用技巧及注意事项。
1.robots.txt文件简介
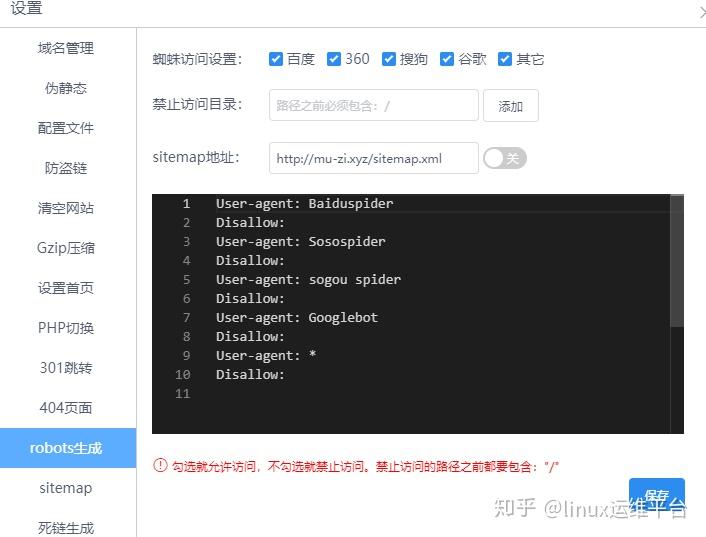
“机器人.txt”实质上是置于网站根目录内的一份纯文本文件,用于指引搜索引擎蜘蛛仅可访问特定页面,限制对其他页面或目录的抓取。这即是遵循“Robots协议”的具体措施,其构建及修缮皆可借助简易文本编辑工具完成。在“机器人.txt”中,最基本的结构由“User-agent”与“Disallow”两大关键词构成,前者为识别特定搜索引擎蜘蛛的规则,后者则明确禁止蜘蛛抓取的页面或目录。
2.百度收录与robots.txt文件
作为我国领先的搜索引擎之一,百度严格遵守Robots协议,透过解析网站的robots.txt文档,来决定应收录或排除哪些网页信息。据此,网站管理者可通过精确设置robots.txt文档,精细化控制百度蜘蛛的访问行为,包括限制特定页面或目录不被百度索引禁止百度收录robots代码禁止百度收录robots代码,确保网站内容的完整性与私密性。
3.禁止百度收录的情况与原因
有时,站长会期望限制百度对特定页面乃至整个目录的收录,其原因涵盖以下几种可能:

-非永久性内容:因某些特殊需求(例如测试页面或短期活动页面),部分网站并不希望其内容被搜索引擎索引。
-尊重隐私:部分页面涉及个人隐私及敏感信息,为确保安全,我们决定将这些页面从搜索引擎索引中移除。
-内链功能:部分链接仅限于内部工作人员或特定受众使用,不宜向公众披露。
4.robots.txt文件配置示例
此为一份简洁但有效的robots.txt文件实例展示,用于阻止百度对特定目录内所有页面进行抓取:
```
User-agent:Baidu
Disallow:/private/
本例中,User-Agent规定了对百度爬虫的策略,Disallow则禁止百度爬虫检索/private/文件夹中的所有页面。
5.robots.txt文件使用技巧
在配置robots.txt文件时,需要注意以下几个技巧:
-运用通配符功能:可使用通配符(如星号"*")实现对某一类网页或文件夹的批量匹配与设置操作。
-多元User-agent设定:可依据特定搜索引擎爬虫需求,实施更为精准的规则管控。
-定期调整:鉴于网站内容变动频发,应相应地频繁对roboats.txt进行修订,使之始终符合当前网站状态。
6.禁止百度收录的注意事项
在禁止百度收录时,需要注意以下几点:
-切忌滥用:不应过度使用robots.txt阻止百度的索引,应遵循合规设计原则,以保障网站正常的排位及流量不受影响。
-验证有效性:在完成robots.txt配置后,应借助如百度站长工具的途径进行生效性的检验,以确认设置达到预定效果。
-详思SEO的影响:禁用某部分页面或目录被百度收录,可能影响网站的SEO成效,需慎重考量。
7.总结与展望
透过深入剖析阻挡百度对网站收录的robots.txt代码,我们揭示了robots.txt文档的基础知识及其与百度收录之间的关联,同时强调了配置文件的技术要点及注意事项。正确应用该文件有助于网站管理者有效管理网站内容,保障用户隐私,提高用户满意度。然而,在实际操作时仍需审慎对待,以防产生不良后果。展望未来,随着网络科技的持续进步,我们期待更为智能、精确的网站管理工具问世,为网站管理者带来更便捷、高效的管理途径。



