
摘要:网上搜了搜,其他一些文章是查询百度跳转链接,然后一个个获取真实链接,再与查询的网址进行匹配,如果能匹配上就说明已收录。我又仔细观察了一下,发现如果百度确实收录了,那么这个网址会在搜索结果的最上方,而且第一条和第二条搜索结果之间会有“以下是网页中包含……”的提示信息。
近日,一位于行业深耕多年的资深编辑打造出一款能准确快速检测百度收录情况的API百度收录查询密令,有效解决了博客行业一直面临的收录效率问题。该项新研发技术不仅提升了检测的速度,更确保其准确性无虞。
原始方法颇具创新性,作者直接通过博客文章访问页面链接,再与百度搜索结果进行比对,以此检验网站的收录情况。然而此法准确性尚待提高,因为百度也可能扩大其检索范畴至其他网页资源。
创新研究策略表明:通过调查及对百度跳跃链接的比对百度收录查询密令,有极大可能发现违规网站。然而,鉴于技术操作上的复杂性,作者未能获得实际跳转链接的精确数据,因此此法尚未得到充分运用。
严谨研究发现,百度将网站收录于索引可助其在搜索结果页首获得显著位置;此外,首页和次页底端均有显示"相关网页链接"引导,从而激发出关于该现象的深层次理论探索。
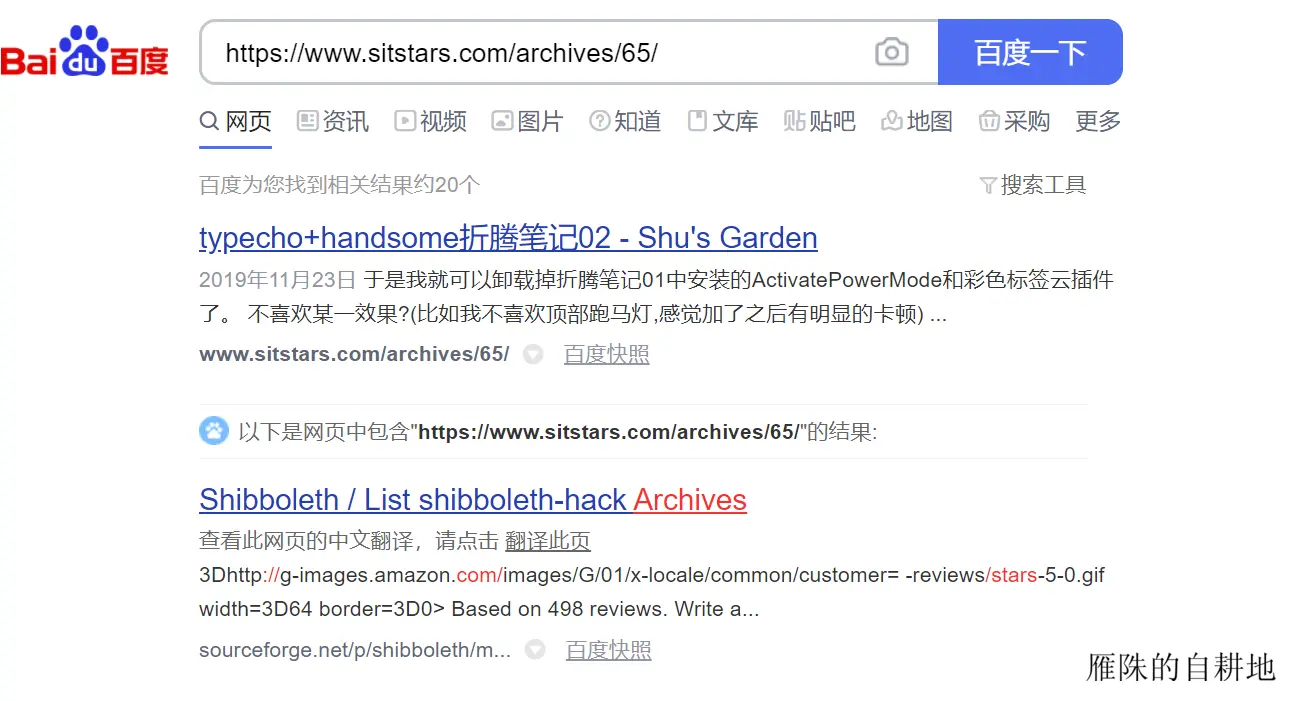
实施方法如下:首先,精确捕捉并确认页面文本在"包含于此网页的所有信息"之前的部分;其次,使用正则表达式以定位到百度搜索链接;最后,一经链接与预设条件匹配成功,即可确定该文章被确认为百度首页收录内容,从而顺利地收录进检索体系。
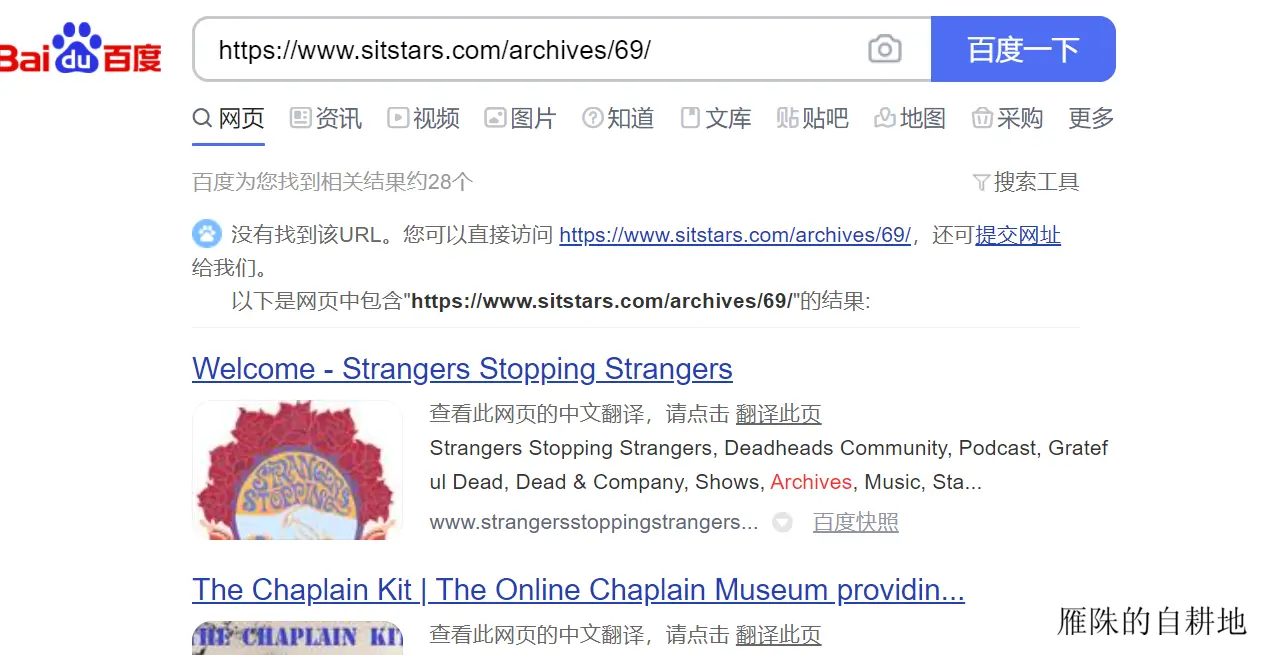
经过严密的测试检验后发现,此方案在此类应用中并无异常现象。随后,作者成功地在服务器端配置部署了API服务,并且相应修改了API的访问路径以适应接下来的测试需求。
据创建人阐述,彼时构想此API的原始动机是发现没法快捷查询博客在百度的收录状况,于是决定将其迁至境内服务器运营。
总结并讨论作者在实践中获取有效网址的方法和可能实现的未来潜在运用价值。
行业专家指出,此项API成功解决了百度博客收录过程中检测效能过低且精度无法满足实际需求的弊端,实现了用户体验及运营效果双重提升,
百度收录检测API因卓越性能及优秀体验广获博主和站长青睐,然亦有部分局限性。尽管面临无结果或重定向失败等问题,但独特特质使其成为博客收录检测的首选工具。展望未来,期待该API持续优化改进。
谨邀同业者共同试用百度收录检测API,分享经验感受以共谋提升文章影响力。本文详细介绍一位资深编辑如何运用此研发成果打造出一款百度收录检测API,现已在国内提供全方位服务。此项实用功能通过解析网页属性抽取百度链接数据,实现了收录监测的高准确性与快速响应。尽管面临众多技术难题及限制,但该API已经赢得了广泛好评,成为了博客平台收录监测的标准工具,助力各大平台实现高效精准的收录解决方案。




